- Sep 17, 2013
- 1,492
AMD has announced an ambitious 2020 goal of a 25-times improvement of the power efficiency of its APUs, the company's term for accelerated processing units – on-die mashups of CPU, GPU, video-accelerator, or any other types of cores.
Although AMD has committed itself to that goal, it won't be an easy one to achieve. Efficiency gains are no longer as automatic as they were in the past, when merely shrinking the chip-baking process resulted in steady improvements.
"The efficiency trend has started to fall off, and it just boils down to the physics," AMD Corporate Fellow Sam Naffziger told The Reg on Friday. "We've scaled the dimensions in the transistors as far as they can go in some respects, and the voltage has stalled out at about one volt."
Robert Dennard's process-scaling guidelines, as outlined in his landmark 1974 paper, have hit a wall, Naffziger said. "The ideal Dennard scaling, where you scale the device in three dimensions and get a factor of four energy improvement, yes, that's at an end. We still get an energy improvement – maybe 30, 50 per cent per generation, which is nice – but it's not what it used to be."
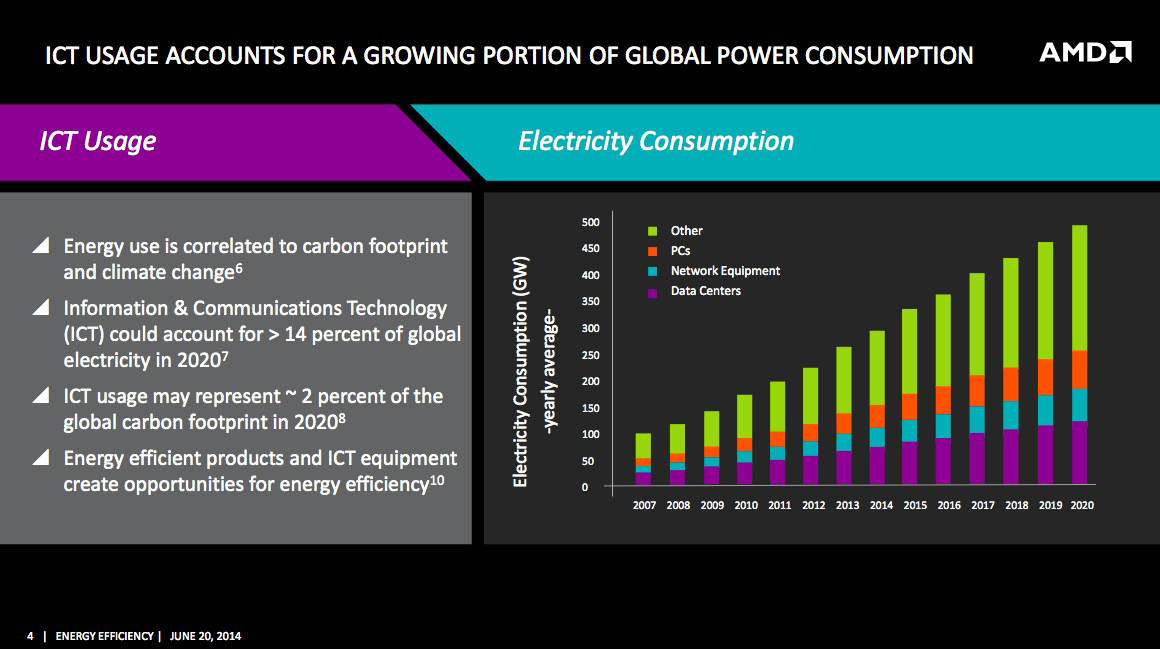
In other words, when it comes to power-efficiency improvements, merely shrinking the chip-baking process isn't going to provide the improvements that are needed to support a world in which the hunger for power by the information and communications technology (ICT) industry is increasing.
And that hunger is voracious. According to work done by Stanford University's Jonathan Koomey, the amount of power needed by ICT is growing fast. The explosion of connected devices, the surging number of internet users, the vast amount of digital content consumption, the need for data-center expansion to handle it – all combine to lead to ICT accounting for over 14 per cent of the world's electricity in 2020, a figure that could account for around 2 per cent of the global carbon footprint that year.

"Our intention," Naffziger said, "is to overcome the slowdown in energy-efficiency gains through intelligent power management and through architectural and software optimizations that squeeze a lot more out of the silicon than we have in the past."
When Naffziger talks about energy efficiency, by the way, he's referring to a metric set by the US Environmental Protection Agency's voluntary Energy Star program called "typical use" efficiency. "There's a definition in the Energy Star specification – a weighted sum of power states that has been shown to be representative of what the power consumption is for typical uses," he said. "What we're doing is optimizing for that typical-use scenario."
According the Naffziger, AMD has improved typical-use power efficiency by about 10 times over the past six years – from 2008's "Puma" to 2014's "Kaveri", both parts being aimed at laptops.
 AMD has done a lot in the past six years, and now plans to more than double its pace (click to enlarge)
AMD has done a lot in the past six years, and now plans to more than double its pace (click to enlarge)
That's good, but not great, Naffziger admitted. Had silicon-scaling's efficiency improvements continued at the same pace they enjoyed during the heyday of Dennard scaling, he said, that increase should have been 14-fold.
"We need to do better, going forward," he said, noting that AMD has a roadmap of how it plans to boost that power-efficiency curve to achieve a 25-times improvement by the end of this decade – an effort the company is calling "25X20".
Not that there hasn't been a lot of good work done in this area by AMD and others. Power management has been made smarter and more fine-grained in recent years, and the trend towards putting more cores and other components onto the same die has reduced power wasted by moving bits back and forth among disparate dies, just to name a pair.
And then there's AMD's embrace of heterogeneous system architecture (HSA) across its product line. Through heterogeneous Uniform Memory Access (hUMA) and heterogeneous Queing (hQ), CPU and GPU cores share the same system memory, with the added efficiency of the CPU not needing to feed the GPU with data – the GPU is smart enough to do so itself, thus increasing efficiency. In addition, using the GPU as a compute core for appropriate tasks allows the APU to save power by offloading those tasks from the less-efficient CPU.
And now the real work begins
But there's much more to come, Naffziger told us. For example, although on-die power management has become smarter over the past few years, there's a lot more efficiency to be squeezed out of it.
Currently, an AMD APU has three primary voltage planes – areas supplied with their own power sources. The more voltage planes you have, the better you can control how much juice your die is consuming.
For example, Naffziger said, the GPU shares a voltage plane with the Northbridge – the memory interface. "A lot of times the GPU isn't doing anything," he said, "but the Northbridge is having to supply data to the CPUs, so you have to keep that voltage plane pretty high."
The GPU is power-gated with on-die switches, he said, but the switches are "imperfect – they're only about 10 per cent efficient – and then there's some things that you just can't power-gate." Solution: separate voltage planes for the GPU, Northbridge, CPU, caches, whatever. More control means more efficiency when each piece of the die gets exactly the voltage it needs.
"Now, that's easier said than done," Naffziger said. The die's smarts need to know exactly what amount of juice to apply exactly where at exactly at the right instant – but subdividing the die into multiple voltage planes is the start.
"Once we've subdivided the voltage planes," he said, "then we can optimize each one of them – and there's a whole bunch of adaptive techniques to use, some of which we've deployed, but most of which are in development that enable that kind of real-time adaptation."
As The Reg explained in our deep dive into AMD's Kaveri chip earlier this month, that chip has thousands of monitors arrayed about its die, some keeping track of temperature, and many more tracking activity and power usage. Information from these monitors are used to boost, throttle, shut down, and maintain die elements, with the goal of operating the chip at maximum efficiency.
 An on-die microcontroller is dedicated to managing data from thousand of sensors (click to enlarge)
An on-die microcontroller is dedicated to managing data from thousand of sensors (click to enlarge)
While that may sound relatively straightforward, it's actually maddeningly complex to optimize the use of the data from those monitors to tune the chip in real time. For just one example, although temperature sensors provide valuable feedback that can be used to adjust power, there's a built-in thermal latency to temperature sensing, a latency not shared by monitors that are simply reporting on activity or power draw.
One solution to this conundrum, Naffziger said, is to use inferences algorithmically derived from power and activity data to proactively deal with impending temperature changes – speeding up the fan, for example, or switching processing from an about-to-be-hot core to a cooler, underutilized one.
"That's one example of the innovations that we're in the early stages of," he said. "There's a lot of opportunity to tune stuff real-time."
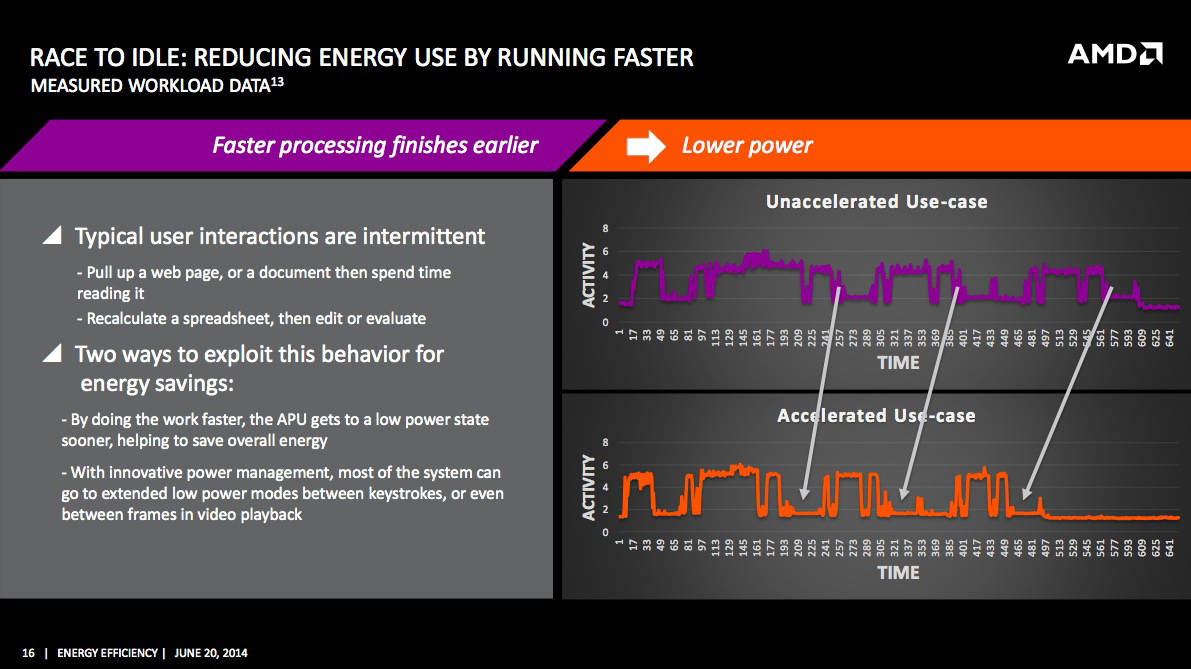
Neffziger also touched on the "race to idle" concept – not a new idea, but one that can increase efficiency by counterintuitively raising the power to enable faster performance for a short amount of time, then dropping the power more quickly than if the core had not been sped up to complete a task in less time.
As an example, he suggested "inter-frame power gating", in which a video frame is quickly rendered, then the renderer is shut down and memory is put into a low-power or sleep state until the next frame. That may also sound somewhat counterintuitive, seeing as how we perceive video frames as a continuous process – but it most certainly isn't continuous from a processor's point of view.
"It's 33 milliseconds," he said, "which is like all day. If rendering a frame takes 5, 10 milliseconds, then you've got 20-plus milliseconds to sit around and do nothing."
 It may sound whack, but you can reduce overall power by selectively boosting power (click to enlarge)
It may sound whack, but you can reduce overall power by selectively boosting power (click to enlarge)
What's more, not all video is created equal, so not all of it requires the same amount of rendering time. An APU's video hardware, however, has to be capable of handling the most-demanding video, so it's over-provisioned, Naffziger told us. For most video, all of that capability isn't needed, so between-frame naps can save a boatload of power.
Each and every optimization requires close coordination between software and hardware teams, and that process can be slow-going. "You'd be surprised how many years it takes. We prototype these, then have to get the bugs wrung out. Generally this is a three-year development cycle," he said.
"To come in and make bold claims about power-efficiency gains wouldn't be credible if we didn't have this pipeline of multi-year IP development now underway," said the man who's "confident" that AMD can achieve a 25X improvement in power efficiency – despite the fact that silicon is less and less on his side.
Although AMD has committed itself to that goal, it won't be an easy one to achieve. Efficiency gains are no longer as automatic as they were in the past, when merely shrinking the chip-baking process resulted in steady improvements.
"The efficiency trend has started to fall off, and it just boils down to the physics," AMD Corporate Fellow Sam Naffziger told The Reg on Friday. "We've scaled the dimensions in the transistors as far as they can go in some respects, and the voltage has stalled out at about one volt."
Robert Dennard's process-scaling guidelines, as outlined in his landmark 1974 paper, have hit a wall, Naffziger said. "The ideal Dennard scaling, where you scale the device in three dimensions and get a factor of four energy improvement, yes, that's at an end. We still get an energy improvement – maybe 30, 50 per cent per generation, which is nice – but it's not what it used to be."
In other words, when it comes to power-efficiency improvements, merely shrinking the chip-baking process isn't going to provide the improvements that are needed to support a world in which the hunger for power by the information and communications technology (ICT) industry is increasing.
And that hunger is voracious. According to work done by Stanford University's Jonathan Koomey, the amount of power needed by ICT is growing fast. The explosion of connected devices, the surging number of internet users, the vast amount of digital content consumption, the need for data-center expansion to handle it – all combine to lead to ICT accounting for over 14 per cent of the world's electricity in 2020, a figure that could account for around 2 per cent of the global carbon footprint that year.
"Our intention," Naffziger said, "is to overcome the slowdown in energy-efficiency gains through intelligent power management and through architectural and software optimizations that squeeze a lot more out of the silicon than we have in the past."
When Naffziger talks about energy efficiency, by the way, he's referring to a metric set by the US Environmental Protection Agency's voluntary Energy Star program called "typical use" efficiency. "There's a definition in the Energy Star specification – a weighted sum of power states that has been shown to be representative of what the power consumption is for typical uses," he said. "What we're doing is optimizing for that typical-use scenario."
According the Naffziger, AMD has improved typical-use power efficiency by about 10 times over the past six years – from 2008's "Puma" to 2014's "Kaveri", both parts being aimed at laptops.
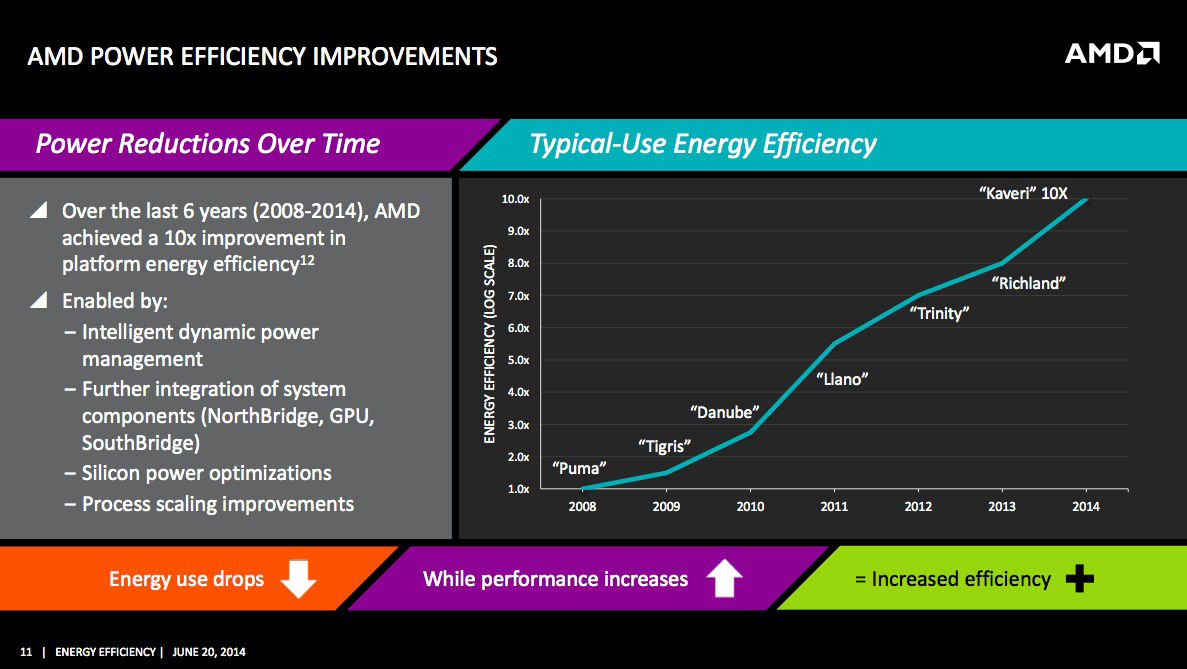
That's good, but not great, Naffziger admitted. Had silicon-scaling's efficiency improvements continued at the same pace they enjoyed during the heyday of Dennard scaling, he said, that increase should have been 14-fold.
"We need to do better, going forward," he said, noting that AMD has a roadmap of how it plans to boost that power-efficiency curve to achieve a 25-times improvement by the end of this decade – an effort the company is calling "25X20".
Not that there hasn't been a lot of good work done in this area by AMD and others. Power management has been made smarter and more fine-grained in recent years, and the trend towards putting more cores and other components onto the same die has reduced power wasted by moving bits back and forth among disparate dies, just to name a pair.
And then there's AMD's embrace of heterogeneous system architecture (HSA) across its product line. Through heterogeneous Uniform Memory Access (hUMA) and heterogeneous Queing (hQ), CPU and GPU cores share the same system memory, with the added efficiency of the CPU not needing to feed the GPU with data – the GPU is smart enough to do so itself, thus increasing efficiency. In addition, using the GPU as a compute core for appropriate tasks allows the APU to save power by offloading those tasks from the less-efficient CPU.
And now the real work begins
But there's much more to come, Naffziger told us. For example, although on-die power management has become smarter over the past few years, there's a lot more efficiency to be squeezed out of it.
Currently, an AMD APU has three primary voltage planes – areas supplied with their own power sources. The more voltage planes you have, the better you can control how much juice your die is consuming.
For example, Naffziger said, the GPU shares a voltage plane with the Northbridge – the memory interface. "A lot of times the GPU isn't doing anything," he said, "but the Northbridge is having to supply data to the CPUs, so you have to keep that voltage plane pretty high."
The GPU is power-gated with on-die switches, he said, but the switches are "imperfect – they're only about 10 per cent efficient – and then there's some things that you just can't power-gate." Solution: separate voltage planes for the GPU, Northbridge, CPU, caches, whatever. More control means more efficiency when each piece of the die gets exactly the voltage it needs.
"Now, that's easier said than done," Naffziger said. The die's smarts need to know exactly what amount of juice to apply exactly where at exactly at the right instant – but subdividing the die into multiple voltage planes is the start.
"Once we've subdivided the voltage planes," he said, "then we can optimize each one of them – and there's a whole bunch of adaptive techniques to use, some of which we've deployed, but most of which are in development that enable that kind of real-time adaptation."
As The Reg explained in our deep dive into AMD's Kaveri chip earlier this month, that chip has thousands of monitors arrayed about its die, some keeping track of temperature, and many more tracking activity and power usage. Information from these monitors are used to boost, throttle, shut down, and maintain die elements, with the goal of operating the chip at maximum efficiency.
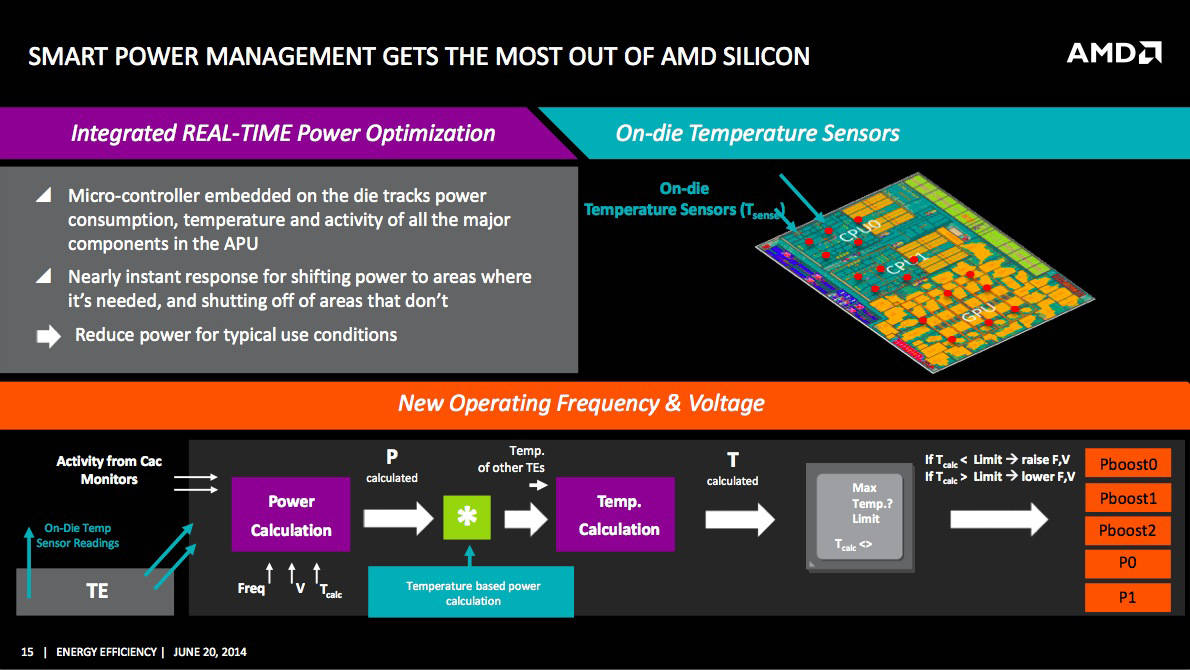
While that may sound relatively straightforward, it's actually maddeningly complex to optimize the use of the data from those monitors to tune the chip in real time. For just one example, although temperature sensors provide valuable feedback that can be used to adjust power, there's a built-in thermal latency to temperature sensing, a latency not shared by monitors that are simply reporting on activity or power draw.
One solution to this conundrum, Naffziger said, is to use inferences algorithmically derived from power and activity data to proactively deal with impending temperature changes – speeding up the fan, for example, or switching processing from an about-to-be-hot core to a cooler, underutilized one.
"That's one example of the innovations that we're in the early stages of," he said. "There's a lot of opportunity to tune stuff real-time."
Neffziger also touched on the "race to idle" concept – not a new idea, but one that can increase efficiency by counterintuitively raising the power to enable faster performance for a short amount of time, then dropping the power more quickly than if the core had not been sped up to complete a task in less time.
As an example, he suggested "inter-frame power gating", in which a video frame is quickly rendered, then the renderer is shut down and memory is put into a low-power or sleep state until the next frame. That may also sound somewhat counterintuitive, seeing as how we perceive video frames as a continuous process – but it most certainly isn't continuous from a processor's point of view.
"It's 33 milliseconds," he said, "which is like all day. If rendering a frame takes 5, 10 milliseconds, then you've got 20-plus milliseconds to sit around and do nothing."
What's more, not all video is created equal, so not all of it requires the same amount of rendering time. An APU's video hardware, however, has to be capable of handling the most-demanding video, so it's over-provisioned, Naffziger told us. For most video, all of that capability isn't needed, so between-frame naps can save a boatload of power.
Each and every optimization requires close coordination between software and hardware teams, and that process can be slow-going. "You'd be surprised how many years it takes. We prototype these, then have to get the bugs wrung out. Generally this is a three-year development cycle," he said.
"To come in and make bold claims about power-efficiency gains wouldn't be credible if we didn't have this pipeline of multi-year IP development now underway," said the man who's "confident" that AMD can achieve a 25X improvement in power efficiency – despite the fact that silicon is less and less on his side.

